基础数据操作之一 关于计算机处理表数据
基础数据操作
我们已经对数据的来源以及轮廓(分布)有了一个基础的了解。下一步就要将这些数据清洗,整理干净。也就是之前提到的 ETL 过程。
这里先展示一个非常简单的示例数据(简单到我们可以口算得到结果)。希望能够通过这个简单的示例和一些小学数学题,激发你对数据操作的一些思考。
示例数据
以下是制作的示例数据:
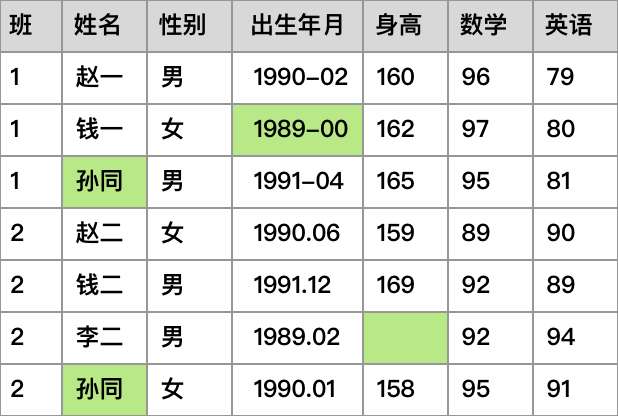
示例数据
这个数据是我们编的,名字里面带"一"的,都是1班的,名字里面带"二"的,都是2班的,另外1班和2班"同"时都有一个特别的"孙同"同学,不过他们重名,不是同一个人。
由于记录前没有统一约定,两个班的日期格式不同,钱一同学的出生年月还被班长错写成了00月,李二同学的身高也被漏记了。
具体的小问题
数据如上所述,很简单。而下面要提出的问题,通过一个个去数,就会得到答案,但这不符合我们的要求。
我们的要求是 -- 要以计算机能够明白的方式来清晰表述解决问题的具体步骤,这样,当数据扩展到几千,几万,几十万,几百万的时候,使用同样的方式就可以了。(暂时忽略当数据特别巨大时可能会有的一些其他问题。)
计算机能够明白的方式?
计算机能够明白的方式?那是什么方式呢?计算机其实很傻,对表格只有几种基础操作,比如,它可以一行行的处理数据,处理第一行,处理第一行的第一列,处理第一行的第二列,... , 等到第一行处理完之后,开始接着处理第二行...直到处理完最后一行的最后一列。 这种一行行处理的,叫做 row-based。
同样也应该可以想到,还有对应另外一种处理方式 -- 就是它可以一列列处理数据,先处理第一列,处理第一列的第一行,第一列的第二行,... ,等到第一列处理完成之后,就开始处理第二列,这种一列列处理的,叫做 column-based。
这两种方式,在处理不同类型的问题时有着不一样的优势。比如,我们想统计每班有多少人,在上面两种处理数据的方式中,显然 column-based 的方式能更快的得到结果。通过设置两个变量来记录次数,第一列第一行是1,那么第一个变量由 0 加 1 得 1;第一列第二行是 1,那么第一个变量由 1 再加 1 得 2,依次类推,它只需要在第一列数据处理完之后,就可以得到结果,而这个问题,如果用 row-based 的处理方式,只有处理到最后一行的第一列,才能得到结果。
前面说的利用两个变量统计次数的计算过程比较简单,不管用 row-based 还是用 column-based,要得到结果都还算轻松,但有的计算过程对于 row-based 和 column-based 就不是同样容易编写了,有可能某个计算过程在column-based 的情况下,只需要寥寥几行就能得出计算结果,而 row-based 的情况则要写的复杂得多,而且容易出错。
在这种情况下,我们如果仍然想利用基于 column 的计算过程来计算某一行的数据,那么我们能做的就是采用一种曲线救国的方法,先把整个表翻转(转置)一下,将中间结果计算完成之后,再转置回去得到最终答案。当然,你也可以去研究一种怎么针对 row 的计算过程,然而,如果已经有了基于 column 的计算过程的情况下,再去研究 row 怎么去算,这件事大概率是不值得做的。
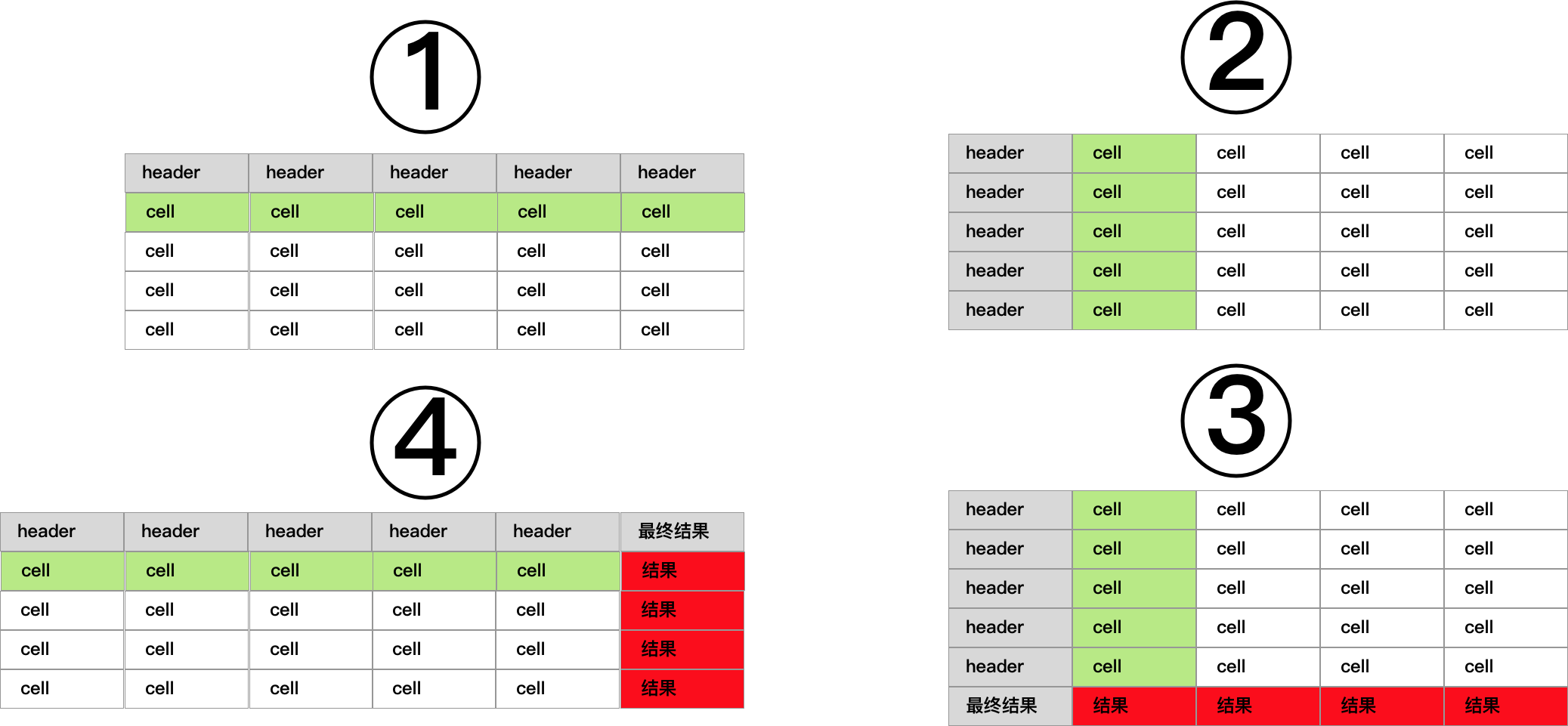
曲线救国
小学数学题列表
好了,你已经知道计算机是怎么处理表的了,要么先行后列,要么先列后行,然后再自己做一些运算,或记录,得到最终结果。 现在想想下面的小学数学题,对应上面所讲的步骤,具体的解决过程究竟是怎样的。
- 想得到只有班级和姓名组成的新表;
- 想得到只有2班同学的新表;
- 想得到姓"李"的同学的新表;
- 想得到2班同学且只有班级和姓名组成的新表;
- 想把上一个问题中得到的表的表头--"班"改成"班级";
- 想把上一个问题中得到的表做的更人性化一点,即把"班级"一列中的,"1"改为"一班","2"改为"二班";
- "李二"缺失的身高怎么办呢?
- 根据英语成绩,由高到低,把两个班的同学排序;
- 得到各个班英语和数学的平均成绩;
- 把上一个问题中得到的平均成绩增加到原表的最后一行中;
- 得到各个班级中,英语最高的同学名单;
- 得到所有女生当中,英语成绩最高的同学的姓名与班级;
- 根据数学成绩把同学区分为优(大于90),良(小于等于90),并计算有多少优,有多少良;
- 怎么把有问题的出生年月改过来?
- 出生年月改过来之后,怎么计算年龄?
小学数学题,对吧?不过你得想一下怎么把小学数学的计算过程一步步给计算机描述清楚。 光说,"显然可见",或者指着表格中的单元,说:"就是这个加这个",这都是不合格的答案。